Crash course on the Kotlin compiler | 1. Frontend: Parsing phase
Lexers, parsers, PSI, AST v. CST, and other fundamental concepts to help understand writing IDE/compiler plugins
As programmers, we like to talk about tech things being a “black box”. For better or worse, the Kotlin compiler feels a bit like one. There is documentation around Kotlin PSI use for IDE plugins, but aside from whatever comments are left in the source code, there’s not too much else out there. It’s my hope that I can help others learn just enough information to get their own elbows dirty (and even encourage others to share what they find).
This mini-series will be released in two parts:
- 1. Frontend: Parsing phase
- 2. Frontend: Resolution phase (coming soon)
- Detour: K1 + K2 Frontends, Backends
The Kotlin compiler is unique in that its frontend is built on top of it, making it easy to share the frontend with both compiler plugins and IDE plugins. For Kotlin, the goal of the frontend is to parse the written code and analyze its interpreted structure so it can generate intermediate representation (IR). This IR, along with additional generated information is then fed to the backend of the compiler¹, which further analyzes, augments, and optimizes the IR before it eventually becomes machine code.
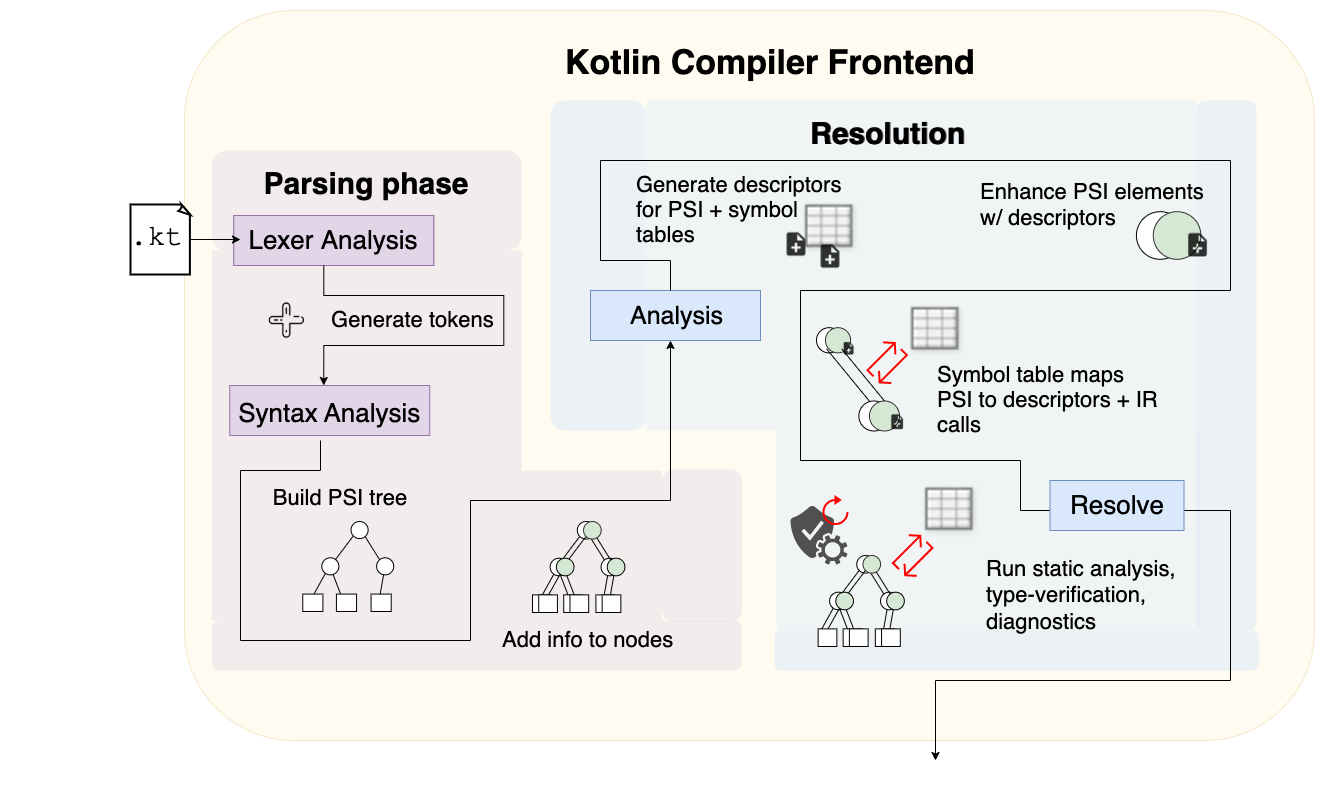
This series observes what happens when you feed code through the Kotlin compiler: it’s the easiest way to understand what the compiler does at each phase. This post covers the first portion of the frontend, the parsing phase.
Parsing Phase
When the source code compiles, the first thing the compiler must do is figure out what exactly the developer had written. Suppose we send the following file through the compiler:
fun main() {
1 + 2
1.plus(2)
}Compilers can “understand” what devs write by parsing and later translating human-readable code into a format the compiler itself can understand. In the image below, a Kotlin file is first fed into the parsing phase. A lexer is created to initially parse the source file and generate tokens. These tokens are then fed through syntax analysis, which in turn creates a PSI structure (explained and qualified more under the Syntax Analysis stage).

At this point, the compiler is not concerned with whether or not the code works — it is only concerned with figuring out what was written in the file. The Parsing phase is responsible for creating syntax trees so the compiler is able to analyze and verify the code later on in the Resolution phase.
The basis of parsing can be seen in the following two-stage process:
- Lexical analysis: The text file is parsed into tokens.
- Syntax analysis: The tokens are parsed and organized /into a syntax tree.
Lexical Analysis
During lexical analysis, the Kotlin parser first creates a KotlinLexer. This lexer scans the Kotlin file and breaks up text into a set of tokens called KtTokens. For example, KtTokens denotes the symbols ( and ) as:
KtSingleValueToken LPAR = new KtSingleValueToken("LPAR", "(");
KtSingleValueToken RPAR = new KtSingleValueToken("RPAR", ")");KotlinExpressionParsing will set up a visitor to arrange these tokens into sets of expression nodes. These expression nodes are then appended to build a PSI tree via ASTNode.
The Programming Structure Interface (PSI) is an abstraction built by JetBrains. It is sort of like a heavy-weight generic syntax tree handling text/code/language in their IDEs. These trees are in-memory representations generated during syntax analysis, and are needed for the compiler to generate additional data and recursively analyze itself for code verification in later phases. PSI is useful for compiler plugins and IDEA plugins alike, since you can filter PSI to intercept specific pieces of code.
In short, the Kotlin parser creates the structure that connects the nodes in a hierarchal relationship. Should KotlinExpressionParsing pick up the key word throw, for example, then another element is parsed and turned into a PSI element to add to the tree:
/*
* : "throw" element
*/
private void parseThrow() {
assert _at(THROW_KEYWORD) PsiBuilder.Marker marker = mark(); advance(); // THROW_KEYWORD parseExpression(); marker.done(THROW);
}
In the next section, syntax analysis will create a PSI parser, which wraps the tokens as PsiElements. Each node holds a description which recursively describes the grammatical structure of the source code.
Syntax Analysis
A generated PSI file describes a hierarchy of PsiElements(so-called PSI trees) that builds syntactic and semantic code models. Is a PSI tree more like an Abstract Syntax Tree (AST) or a Concrete Syntax Tree (CST)? Well, it seems that a generated PSI tree possesses characteristics for both.
Eli Bendersky’s blog on Abstract v. Concrete Syntax Trees does a great job of explaining the difference between the two in greater detail. Like a CST tree, a PSI structure contains a more formal representation of what has been written, including symbols. However, like an AST, the PSI tree holds additional useful information in each node itself.
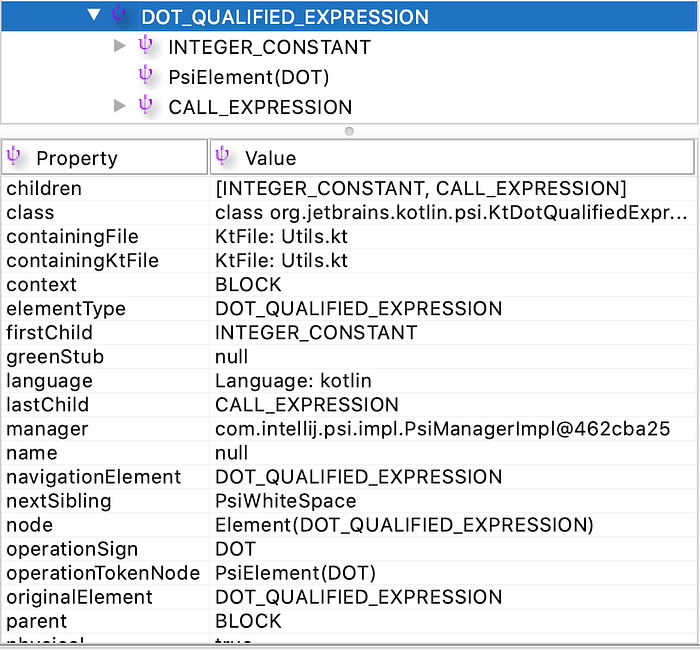
In IntelliJ IDEA, you can download the plugin PSIViewer to inspect the PSI of the code you write. You can also highlight parts of your code to see what the PSIViewer selects in its rendered tree.
The image below shows how PSIViewer interprets 5.minus(2) as a DOT_QUALIFIED_EXPRESSION, whose first child is anINTEGER_CONSTANT as 5 , second child DOT for ., and third childCALL_EXPRESSION as minus(2).
These PSI elements contains tokens, and is able to hold information on child and parent elements it might hold relation to. These PSI structures become even more sophisticated as the compiler builds and generates additional information from it. PSI structures share characteristics for both CST and AST, although their structures become more AST-like over time. For the sake of discussion and convenience, we shall refer to these trees in terms of AST.
Consider the expression 5 — 2. The generated AST is the following, where the darker nodes of the tree are represented as elements and the lighter nodes are represented as tokens.
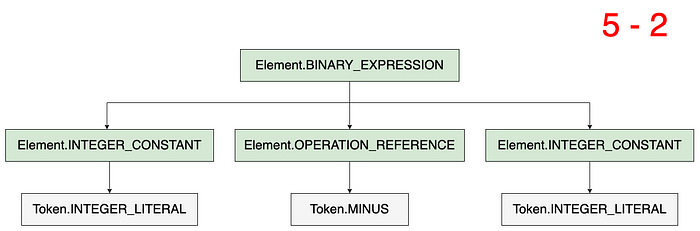
The expression 5 – 2 can be broken down into a binary expression comprised of two integer constants as operands and an OPERATION_REFERENCE as an operator. But the expression 5.minus(2) , even if it evaluates to the same result as 5 — 2, would have a different AST structure altogether.
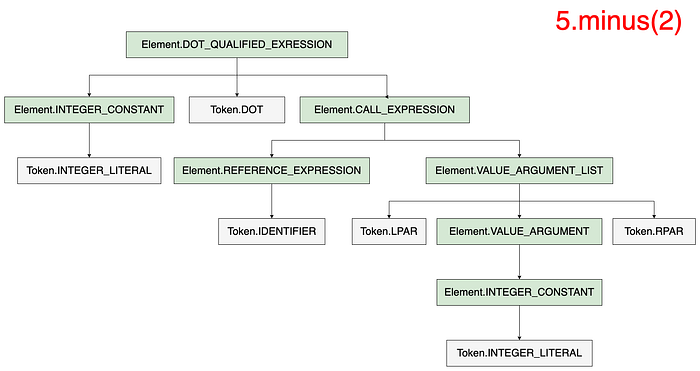
The PSI tree tells us how the code has been written by the end user, but not much else at this stage. This means that at this point, the compiler can only tell us how the code has been written, but it does not know if the code compiles or not.
A PSI tree can be built whether or not the code is correct. Consider the screenshot of the IntelliJ IDEA below. The left portion of the pane shows the code in Utils.kt. Inside the main function, there are two statements, with the second line of the function being 5.((2) instead of 5.minus(2). We know (and the IDE knows) that such a statement like 5.((2) will not compile. But remember, the PSI tree does not need to know this. It will generate the elements anyway, although it may not be able to accurately interpret hierarchy relationships within.

How is the IDE able to give us the red squiggly line in the lefthand pane of the screenshot? That is just what the Resolution phase is responsible for, which gives us the perfect segue for the topic of the next post. The next article will look into the Resolution phase, which creates the necessary analysis needed to help figure out whether the code can compile or not. Stay tuned!
Much thanks to Leland Richardson for his review providing feedback around compiler details and Louis CAD for his review and feedback around the article/diagrams.
Want more on the Kotlin Compiler?
- KotlinConf ’23: Crash Course on the Kotlin Compiler by Amanda Hinchman-Dominguez now out on YouTube
- Github repo — Kotlin-Compiler Crash Course for all research notes around the Kotlin compiler
¹ The backend then takes this IR, optimizes it, optimizes it again, and generates all of it into bytecode. This will be covered in the next post.

